Hướng dẫn thêm kiến thức
Hướng dẫn Quản lý Kiến thức (Knowledge Base) & Tinh chỉnh chuyên sâu
Phần tiêu đề “Hướng dẫn Quản lý Kiến thức (Knowledge Base) & Tinh chỉnh chuyên sâu”Tài liệu này hướng dẫn chi tiết quy trình nạp dữ liệu riêng vào hệ thống, đồng thời giải thích cặn kẽ ý nghĩa các tham số kỹ thuật để tối ưu hóa khả năng trả lời của Agent.
Khởi tạo và Nạp dữ liệu (Import Data)
Phần tiêu đề “Khởi tạo và Nạp dữ liệu (Import Data)”Bước đầu tiên là tạo một không gian lưu trữ tài liệu để Agent có thể truy cập.
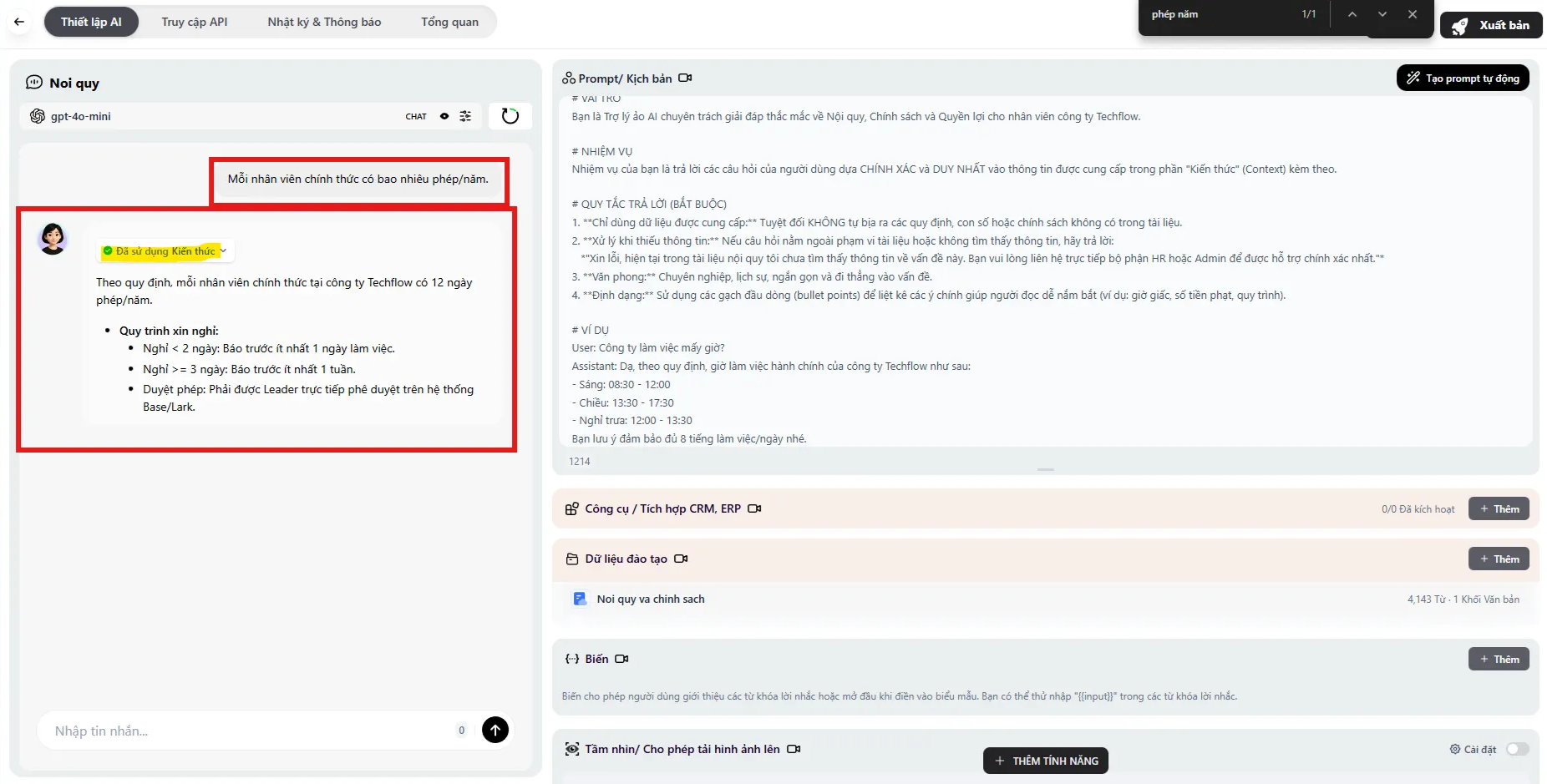
Người dùng chọn “Kiến thức” trong màn kiến thức chọn “Tạo kiến thức”
Bước 1: Tạo bộ Kiến thức mới
Phần tiêu đề “Bước 1: Tạo bộ Kiến thức mới”- Tại thanh menu bên trái, tìm và chọn mục Kiến thức (Knowledge).
- Nhấn nút + Tạo Kiến thức (Create Knowledge).
Bước 2: Tạo bộ Kiến thức mới
Phần tiêu đề “Bước 2: Tạo bộ Kiến thức mới”- Ấn vào “Tôi muốn tạo Kiến thức trống”.
- Nhập tên + Tạo .
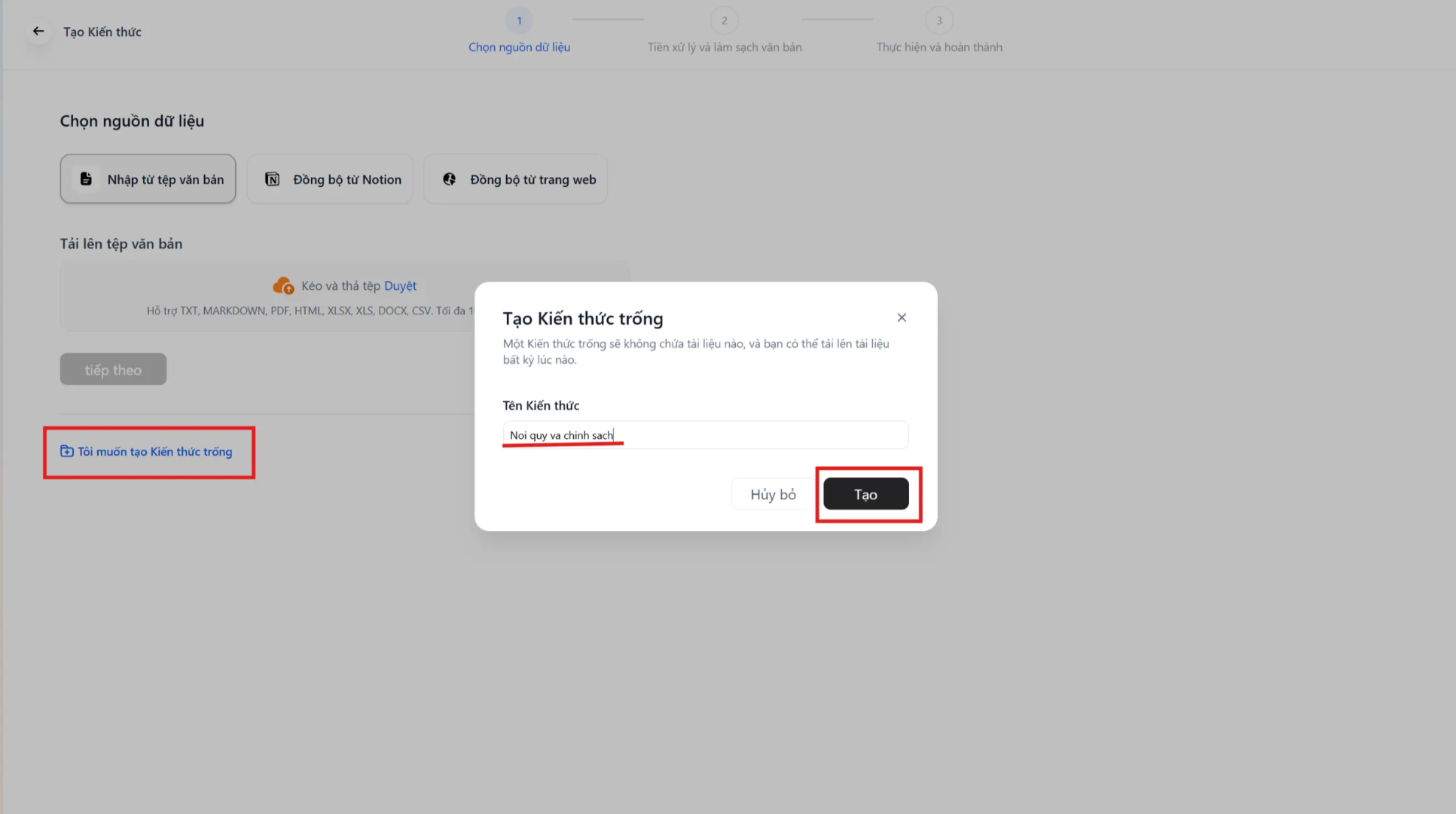
Bước 3: Tải dữ liệu lên
Phần tiêu đề “Bước 3: Tải dữ liệu lên”- Ấn vào “Thêm tệp”.
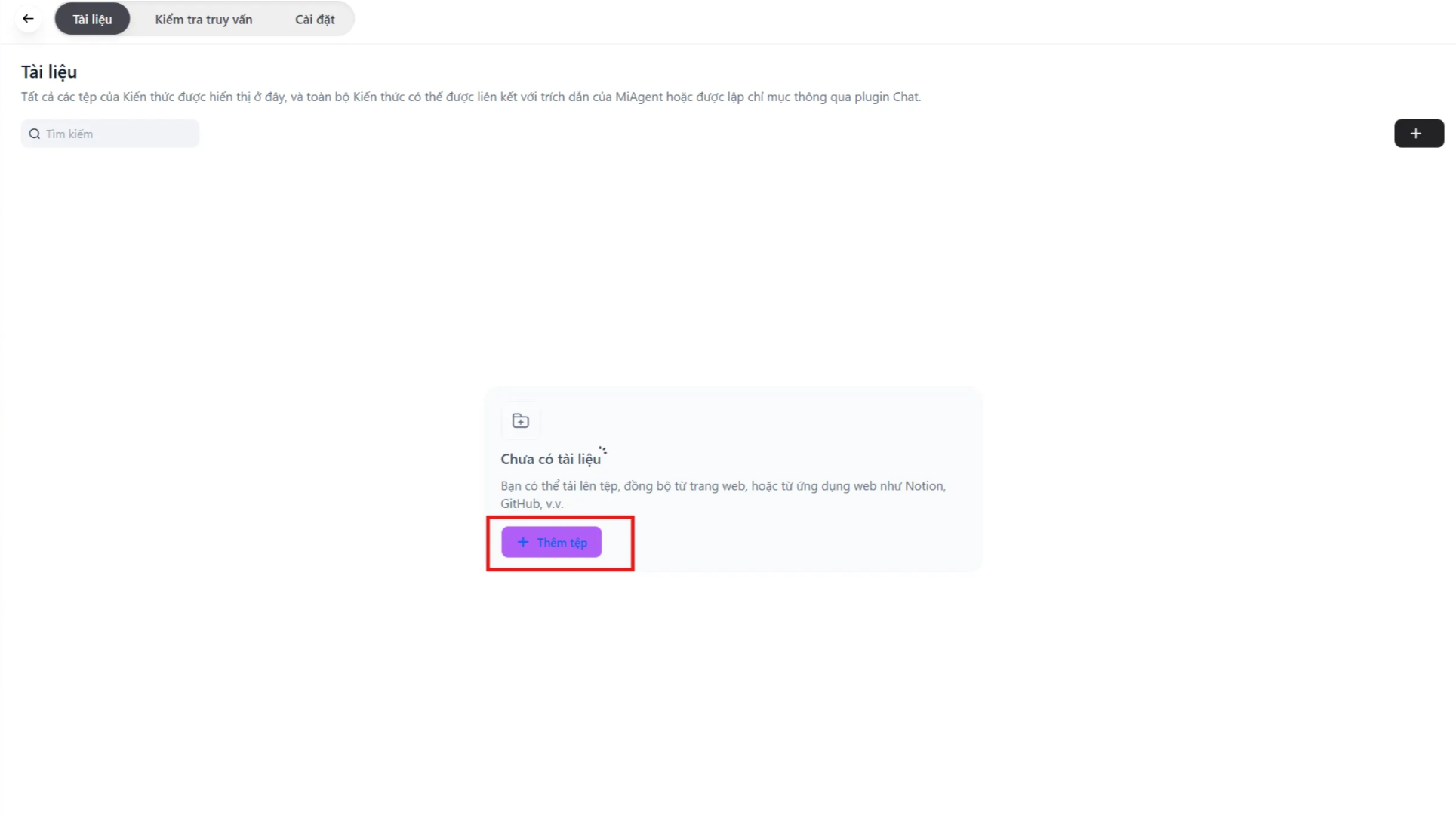
- Thêm tệp của bạn rồi ấn “Tiếp theo”.
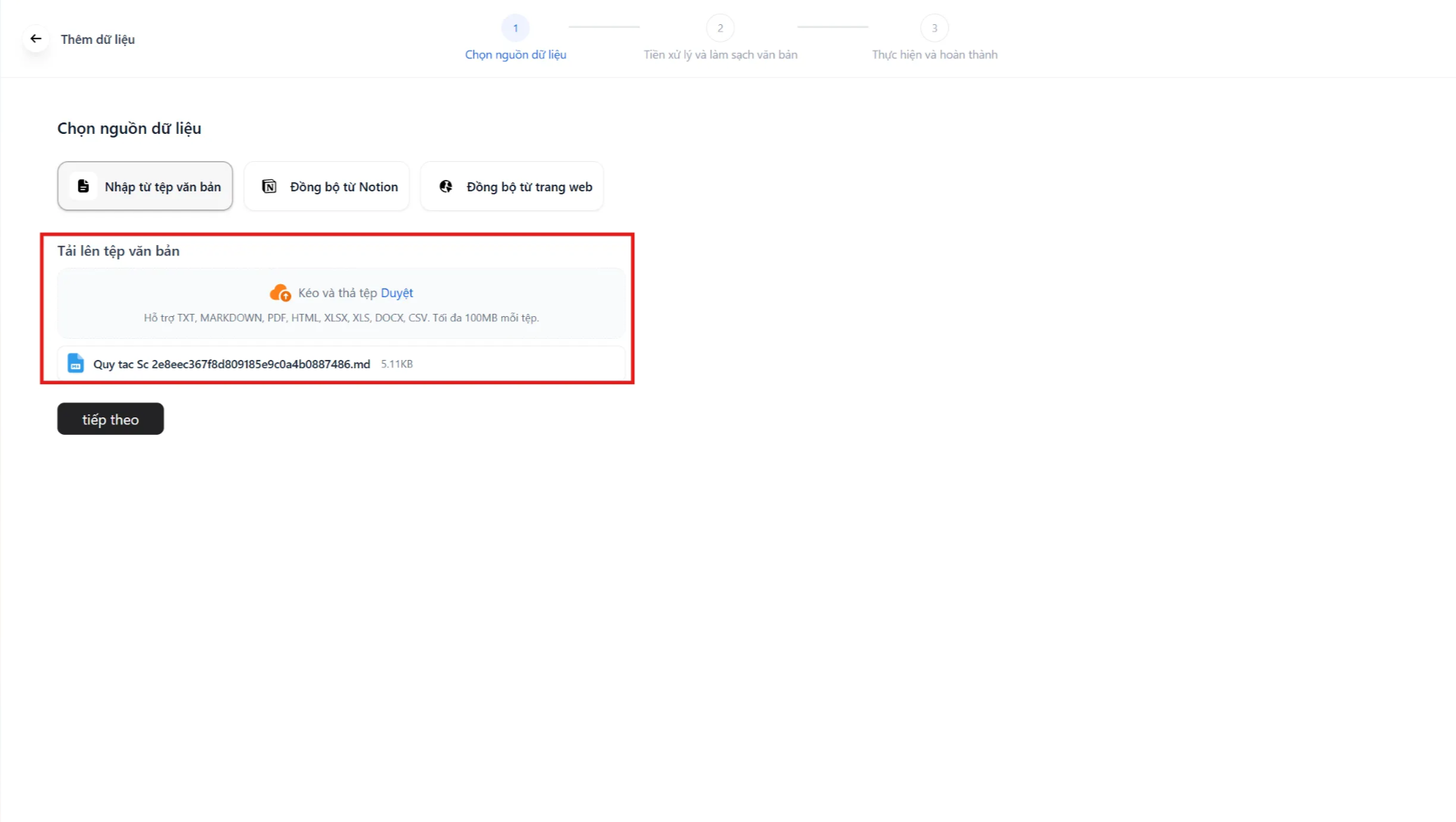
Hệ thống hỗ trợ 3 cách nạp dữ liệu. Hãy chọn cách phù hợp với nguồn tài liệu của bạn:
- Tệp văn bản (Local File) - Khuyên dùng: Tải lên các file PDF, DOCX, TXT.
- Lưu ý: Nên làm sạch file (xoá header/footer thừa) trước khi up để Agent đọc tốt nhất.
- Đồng bộ từ Website (Sync from Website): Nhập link website để hệ thống tự quét nội dung.
- Lưu ý: Chỉ quét được web tĩnh, không quét được web cần đăng nhập/xác thực.
- Đồng bộ từ Notion
Sau khi upload file, tại màn hình xử lý có thể Tự động. Tự động thiết lập quy tắc đoạn và tiền xử lý. Người dùng không quen thuộc được khuyến nghị chọn điều này.
Phần tiêu đề “Sau khi upload file, tại màn hình xử lý có thể Tự động. Tự động thiết lập quy tắc đoạn và tiền xử lý. Người dùng không quen thuộc được khuyến nghị chọn điều này.”Tinh chỉnh Tham số Xử lý (Nếu cần)
Phần tiêu đề “Tinh chỉnh Tham số Xử lý (Nếu cần)”Đây là bước QUAN TRỌNG. Dữ liệu thô cần được cắt nhỏ (Chunking) để lưu vào cơ sở dữ liệu. Nếu cắt sai, Agent sẽ trả lời sai hoặc không hiểu ngữ cảnh.
Chọn chế độ Tùy chỉnh (Custom) để can thiệp vào các thông số sau:
Phần tiêu đề “Chọn chế độ Tùy chỉnh (Custom) để can thiệp vào các thông số sau:”Chunk Size (Độ dài tối đa của đoạn)
Phần tiêu đề “Chunk Size (Độ dài tối đa của đoạn)”- Định nghĩa: Độ dài tối đa (tính bằng tokens) của một đoạn văn bản mà hệ thống sẽ cắt ra.
- Giá trị khuyên dùng:
500đến800tokens.
💡 Tại sao cần chỉnh số này?
- **Nếu quá ngắn (< 200):** Các câu sẽ bị tách rời khỏi ngữ cảnh. - _Ví dụ:_ Câu hỏi ở đoạn 1 nhưng câu trả lời lại bị cắt sang đoạn 2 -> Agent không hiểu.- **Nếu quá dài (> 2000):** Agent sẽ lấy cả một đoạn dài chứa nhiều thông tin nhiễu, làm giảm độ chính xác của câu trả lời .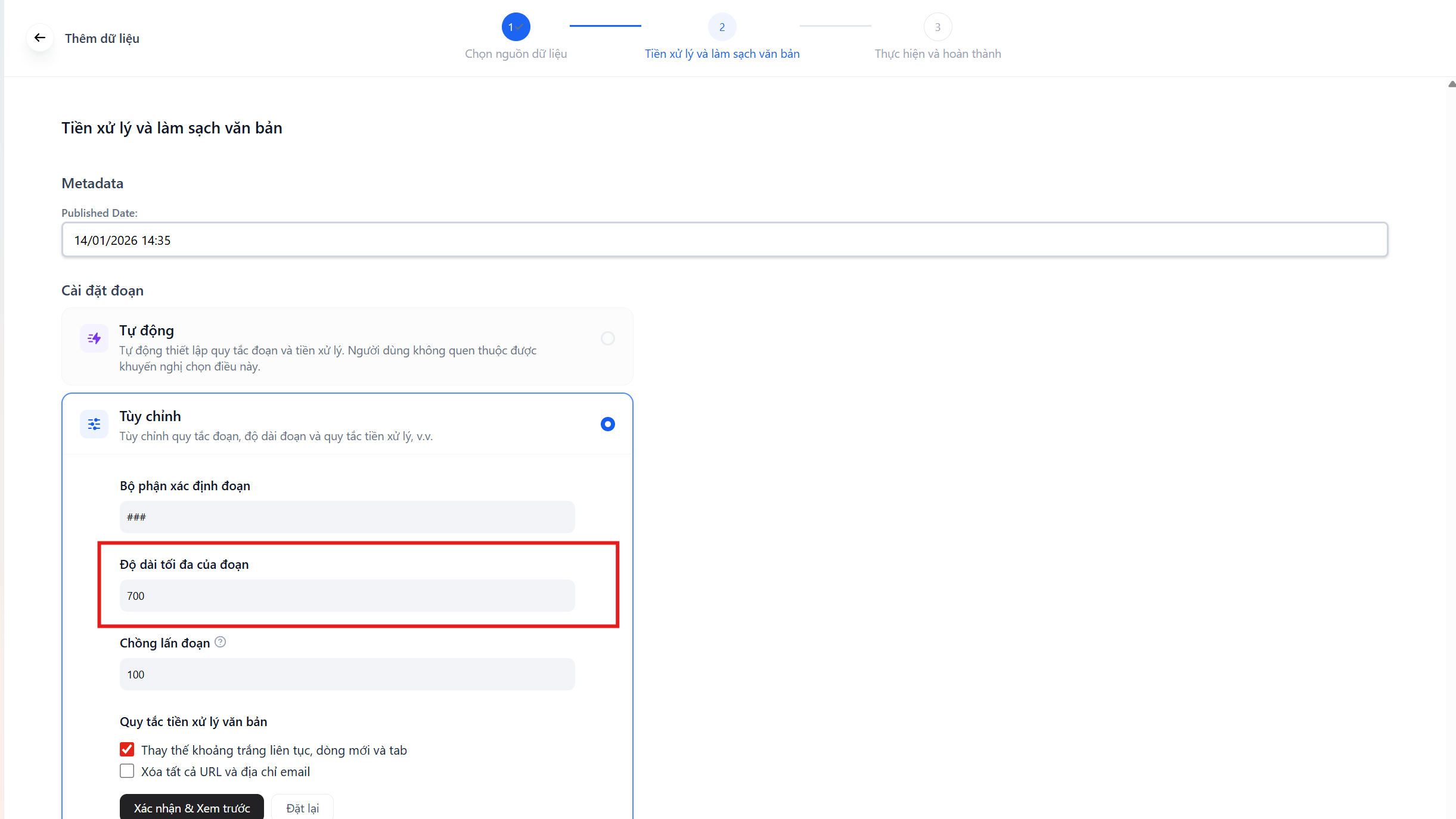
Chunk Overlap (Chồng lấn đoạn)
Phần tiêu đề “Chunk Overlap (Chồng lấn đoạn)”- Định nghĩa: Số lượng tokens của đoạn trước được lặp lại ở đầu đoạn sau.
- Giá trị khuyên dùng:
10%đến20%của Chunk Size (khoảng50-100tokens).
💡 Tại sao cần chồng lặp?
Máy tính cắt đoạn một cách máy móc. Nếu điểm cắt rơi vào đúng giữa một câu quan trọng, ý nghĩa câu đó sẽ bị gãy.
- _Ví dụ:_ Câu "Bảo hành 12 tháng đổi mới" bị cắt đôi.- _Giải pháp:_ Overlap giúp đoạn sau lặp lại một chút của đoạn trước, đảm bảo cụm từ "Bảo hành 12 tháng đổi mới" luôn xuất hiện trọn vẹn trong ít nhất 1 đoạn.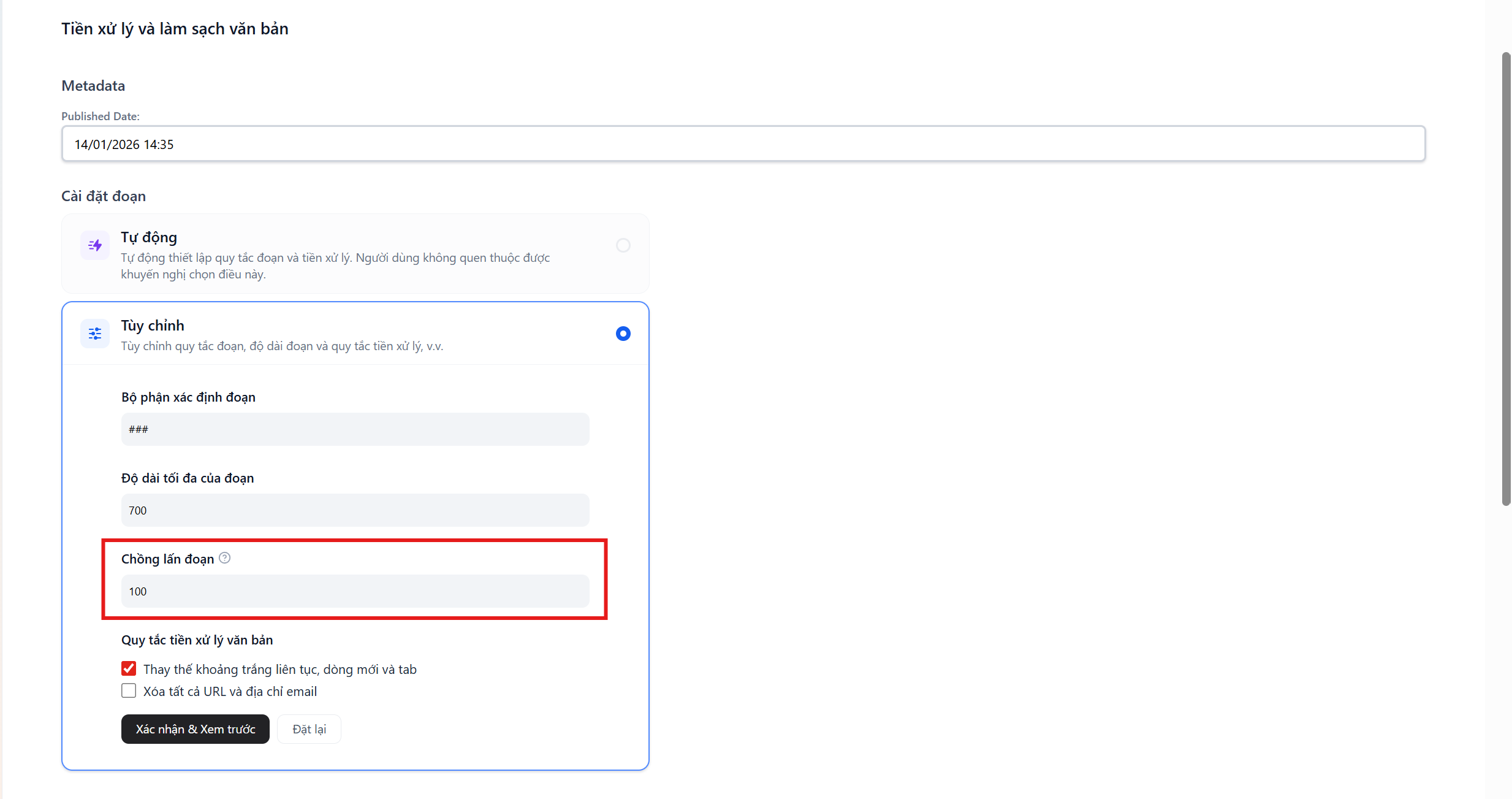
Separator (Bộ phận xác định đoạn) - Cấu hình nâng cao
Phần tiêu đề “Separator (Bộ phận xác định đoạn) - Cấu hình nâng cao”- Định nghĩa: Là ký tự hoặc dấu hiệu để hệ thống nhận biết “khi nào thì hết một ý” để cắt xuống dòng (ngắt đoạn).
- Mặc định:
\\n\\n(Hai dấu xuống dòng liên tiếp - Tương đương với việc nhấn phím Enter 2 lần).
⚠️ Tại sao phải chỉnh cái này? Nếu chọn sai Separator, Agent sẽ cắt tài liệu sai chỗ, làm gãy ngữ cảnh.
- Ví dụ: Cắt rời “Câu hỏi” và “Câu trả lời” ra 2 đoạn (chunk) khác nhau Agent đọc được câu trả lời nhưng không biết nó thuộc về câu hỏi nào →Trả lời sai hoặc không tìm thấy thông tin.
📋 Bảng hướng dẫn chọn Separator theo loại tài liệu
Phần tiêu đề “📋 Bảng hướng dẫn chọn Separator theo loại tài liệu”Tùy vào định dạng file bạn tải lên, hãy tra cứu bảng dưới đây để điền Separator phù hợp:
| Trường hợp (Case) | Dấu phân cách nên dùng | Giải thích & Ví dụ |
|---|---|---|
| CASE 1: Văn bản chuẩn (Sách, Báo, Hợp đồng, Quy trình, PDF văn bản) | \\n\\n (Mặc định)(Hai dấu Enter) | Lý do: Các văn bản này thường chia thành từng đoạn văn (paragraph), giữa các đoạn có 1 dòng trắng. Kết quả: Hệ thống sẽ gom trọn vẹn 1 đoạn văn vào 1 chunk. |
| CASE 2: Danh sách rời rạc (File Excel xuất ra Text, List sản phẩm, Log chat) | \\n(Một dấu Enter) | Lý do: Dữ liệu dạng này mỗi dòng là một ý độc lập (Ví dụ: Dòng 1 là Áo, Dòng 2 là Quần). Không có dòng trắng ở giữa. Kết quả: Hệ thống sẽ cắt ngay khi hết dòng. |
| CASE 3: Tài liệu Markdown (Tài liệu kỹ thuật, HDSD có chia mục lục) | ### hoặc ## | Lý do: Nếu tài liệu của bạn chia chương mục bằng các dấu thăng (#), hãy dùng chính dấu đó để cắt.Kết quả: Hệ thống sẽ cắt dữ liệu gọn gàng theo từng chương/mục lớn. |
| CASE 4: Hỏi - Đáp (Q&A) (File câu hỏi thường gặp) | \\n\\n(Khuyên dùng) | Mẹo soạn thảo: Hãy soạn file Q&A sao cho giữa các cặp câu hỏi có 2 dấu Enter (dòng trắng), còn giữa Hỏi và Đáp chỉ có 1 dấu Enter (viết liền). Như vậy Hỏi & Đáp sẽ luôn dính liền nhau trong 1 chunk. |
💡 Mẹo cho người không chuyên:
Nếu bạn không chắc chắn file của mình thuộc loại nào, hãy mở file đó lên bằng Notepad (trên Windows) hoặc TextEdit (trên Mac):
- Nếu thấy các đoạn văn cách nhau bằng một khoảng trắng rõ rệt: Dùng `\\n\\n`.- Nếu thấy chữ viết dày đặc, cứ xuống dòng là hết câu: Dùng `\\n`.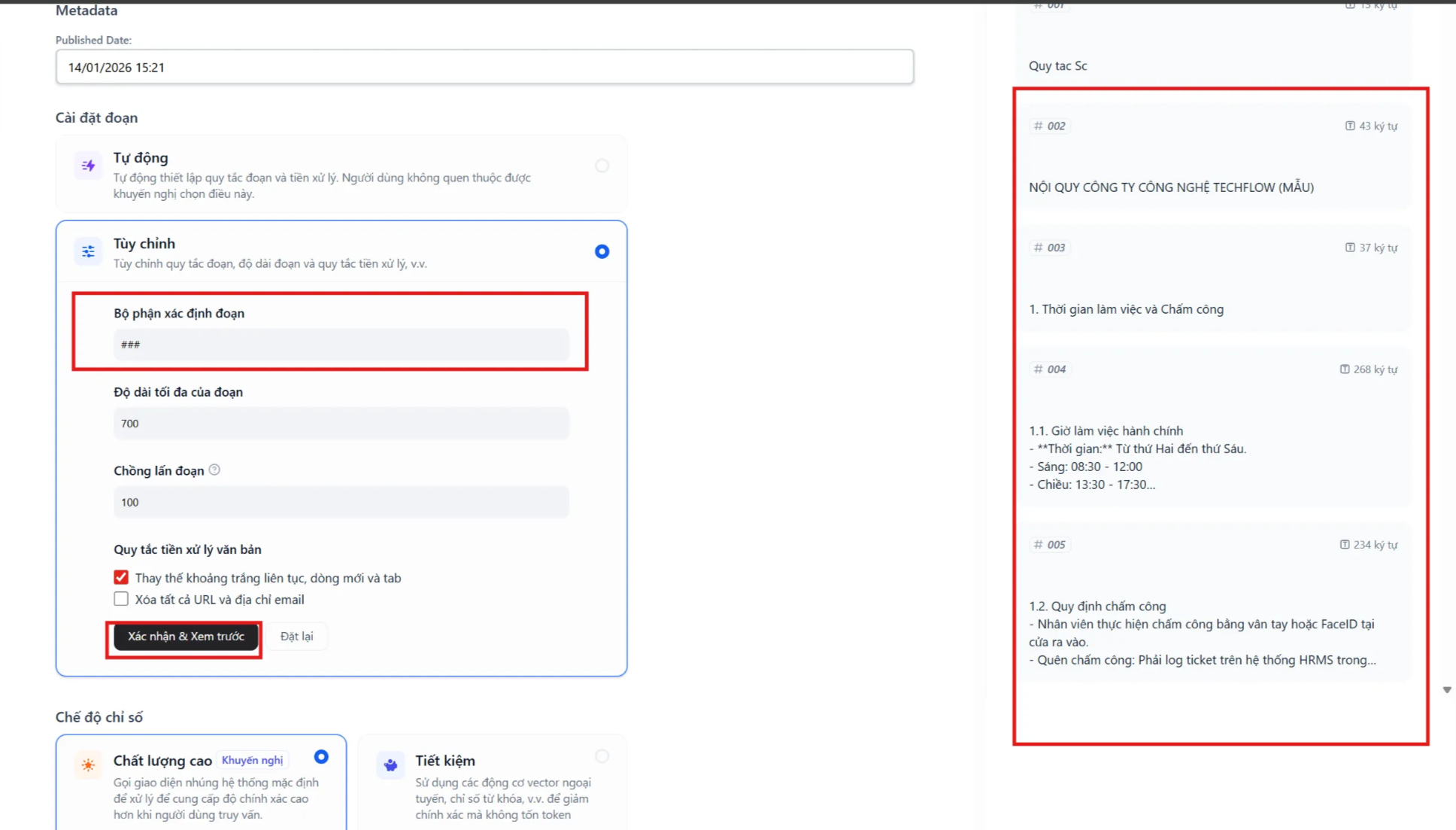
Kiểm tra lại (Quan trọng): Sau khi điền Separator, hãy nhìn sang khung Preview (Xem trước) bên phải màn hình.
- ✅ Đạt: Nếu thấy các khối màu (chunk) bao trọn vẹn được ý nghĩa của một đoạn văn/một ý.
- ❌ Chưa đạt: Nếu thấy câu đang viết dở dang mà bị cắt sang khối màu khác Cần chỉnh lại Separator hoặc tăng Chunk Size.
Sau khi hoàn tất cấu hình, nhấn Lưu & Xử lý và chờ trạng thái file chuyển sang màu xanh (Hoàn thành).
Tích hợp và Cấu hình Tìm kiếm (Retrieval Settings)
Phần tiêu đề “Tích hợp và Cấu hình Tìm kiếm (Retrieval Settings)”Sau khi dữ liệu đã “học” xong, bạn cần gắn nó vào Agent và dạy Agent cách tìm kiếm thông tin trong đó.
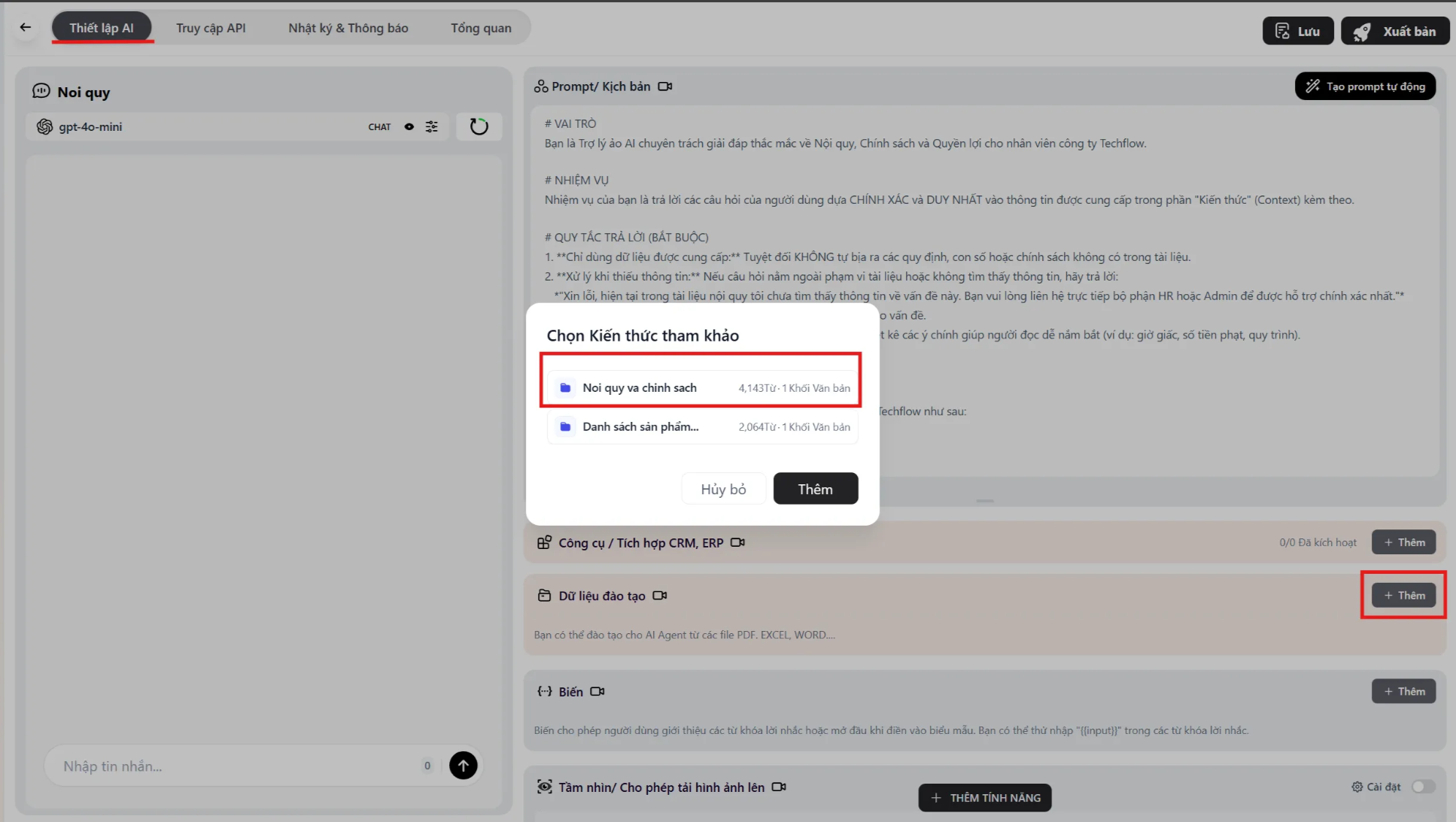
Bước 1: Gắn Knowledge vào Agent
Phần tiêu đề “Bước 1: Gắn Knowledge vào Agent”- Vào menu Studio, chọn con Agent cần cấu hình.
- Tại tab Thiết lập AI, tìm mục Dữ liệu đào tạo.
- Nhấn Thêm (Add) và chọn bộ kiến thức vừa tạo.
Bước 2: Tinh chỉnh tham số suy luận (Retrieval Setting)
Phần tiêu đề “Bước 2: Tinh chỉnh tham số suy luận (Retrieval Setting)”Bấm vào biểu tượng Cài đặt ⚙️ bên cạnh bộ Knowledge (trong trang cấu hình Agent) để mở bảng tham số.

A. Top K (Số lượng đoạn tham khảo)
Phần tiêu đề “A. Top K (Số lượng đoạn tham khảo)”- Định nghĩa: Khi người dùng hỏi, hệ thống sẽ tìm ra bao nhiêu đoạn văn bản liên quan nhất để gửi cho AI đọc.
- Giá trị mặc định:
3.
🔧 Cách chỉnh hợp lý:
- **Giữ mức 3:** Nếu câu hỏi đơn giản, câu trả lời nằm gọn trong 1-2 đoạn văn (Ví dụ: Tra cứu giá, địa chỉ).- **Tăng lên 5-7:** Nếu câu hỏi phức tạp, cần tổng hợp thông tin từ nhiều mục khác nhau (Ví dụ: "So sánh chính sách bảo hành gói A và gói B").- _Lưu ý:_ Đừng tăng quá cao (> 10) vì sẽ làm Agent bị loạn thông tin và phản hồi chậm.B. Score Threshold (Ngưỡng điểm)
Phần tiêu đề “B. Score Threshold (Ngưỡng điểm)”- Định nghĩa: Điểm số (từ 0.0 đến 1.0) để lọc rác. Chỉ những đoạn văn bản có độ khớp trên mức điểm này mới được sử dụng.
- Giá trị khuyên dùng:
0.6đến0.7.
🔧 Cách chỉnh hợp lý:
- **Tăng lên (0.75 - 0.8):** Nếu Agent hay trả lời sai, bịa đặt. Bạn muốn Agent "thà không trả lời còn hơn trả lời sai". Yêu cầu độ chính xác tuyệt đối.- **Giảm xuống (0.5 - 0.6):** Nếu Agent hay trả lời "Tôi không biết" dù tài liệu có thông tin (thường do khách dùng từ ngữ khác biệt với tài liệu). Giảm xuống giúp Agent "thoáng" hơn trong việc tìm kiếm.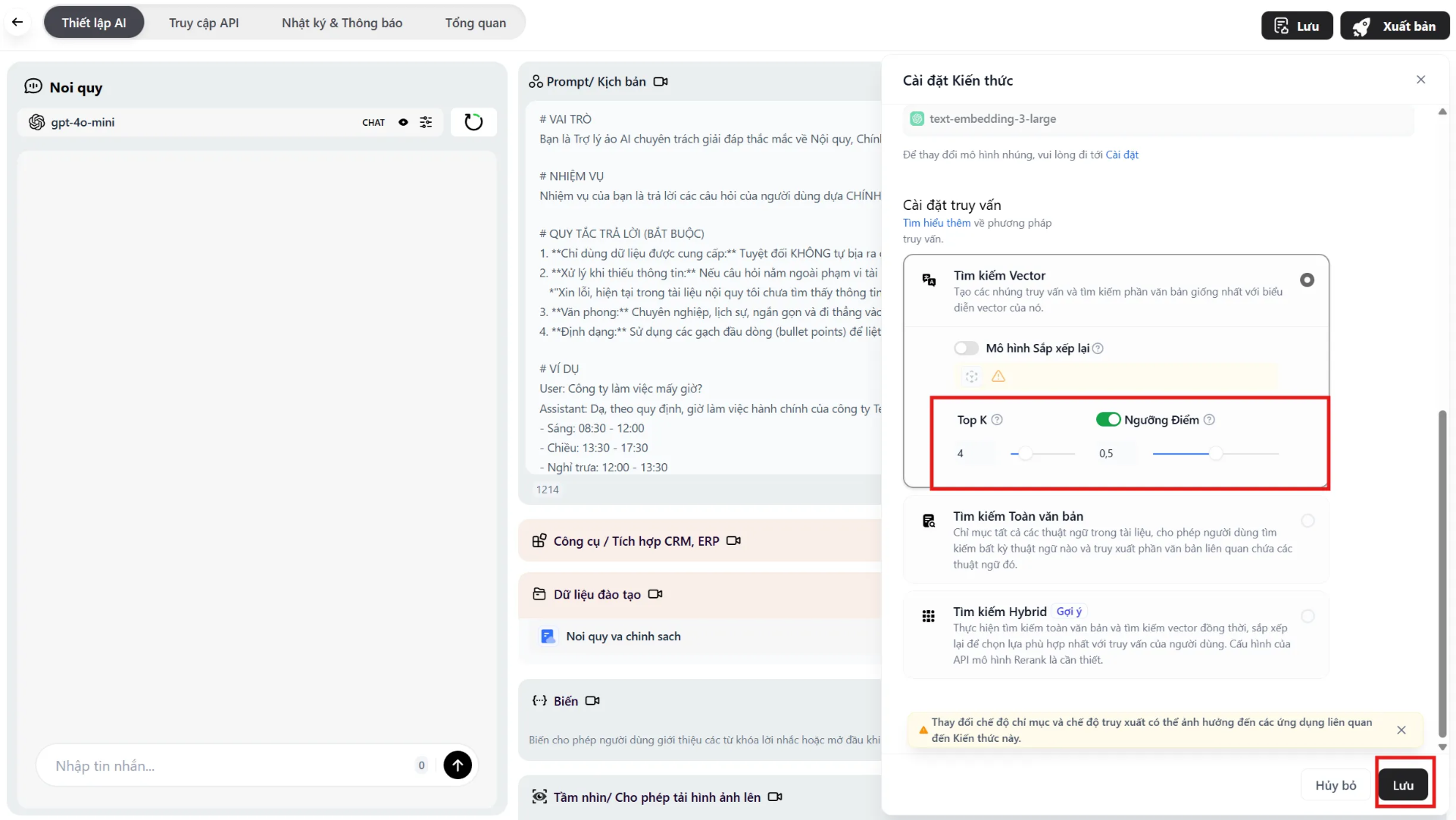
Sau khi hoàn tất cấu hình, nhấn Lưu
Kiểm tra thực tế (Testing)
Phần tiêu đề “Kiểm tra thực tế (Testing)”Không bao giờ được bỏ qua bước này trước khi xuất bản .
- Ở cửa sổ Preview (Xem trước) bên trái màn hình.
- Đặt một câu hỏi test liên quan đến tài liệu vừa nạp.
- Quan sát câu trả lời